本文共 5140 字,大约阅读时间需要 17 分钟。
介绍
本文由浅入深的介绍DFS,以及由些引深到访问者模式。看完本文,你会有如下收获
- 学习到一种通用的解题思想,帮你解决leetcode一类题
- 学习到回溯算法的本质
- 带你重新认识树的遍历
- 更进一步的理解访问者模式的本质
一、Walk与Visit思想
这里,使用一个直观的现实例子来说明Walk与Visit思想
1. 一个比喻
我们假设有这样一个小区,小区中的房子都是一座座独立的别墅。这个小区的组织形式呢,有点怪,以树的结构进行组织,就像下图这样
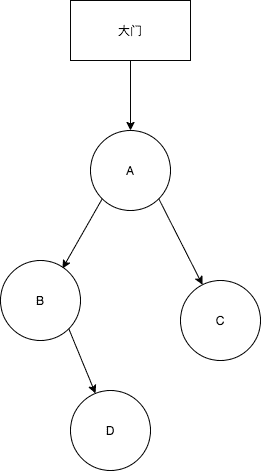
在这里
树的结点-->别墅
树的分支-->连接别墅的道路
2. Walk顺序
假设张三从大门进入来到了这个小区,他要在这个小区散步,散步的习惯就是深度优先,则其经过的别墅顺序为,
A->B->Null->D-Null->Null->C->Null->Null复制代码
(之所以添加null是为了下文中讨论Visit时机时方便, 同时也可以让代码更容易理解与简化,这里可以先忽略)
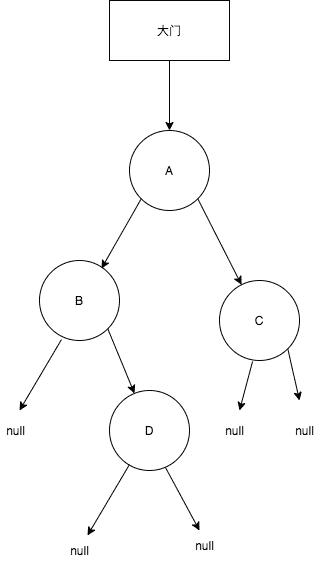
而以上的顺序称之为Walk顺序,其实就是深度遍历的顺序(注意, 这里只是经过别墅,并没有进入别墅).
而对于一个给定的树来说,深度遍历的顺序是固定的。
3. Visit时机
如果说, 当张三经过某一别墅时, 决定进入别墅拜访主人, 或者进入别墅做一些其它事情的话,我们将要做的事情抽象为Visit操作, 对于每一个别墅来说,Visit的时机, 有三种可能. 如下图所示
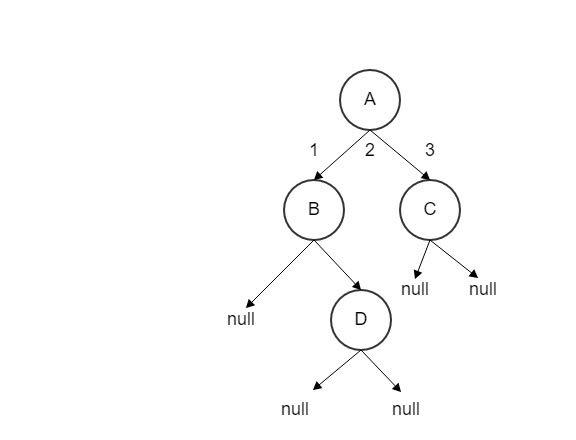
对于A, 对于A其时机可以是
时机1:走到B之前,还未打算散步到那里
时机2:从B返回,但还没打算前往C
时机3:从C返回
如果使用代码描述Walk顺序与Visit时机, 则是这个样子的.
void walk(TreeNode node) { //时机1,还没前往B walk(node.left); // 这时,到达了B //时机2, 已经从B返回 walk(node.right); // 这时,到达了C //时机3, 也从C返回了 return;}复制代码 当程序中调用walk(TreeNode A)时, 可以认为到达了结点A.
当涉及到树的结构时, 可以根据不同的需要选择一个或多个时机, 对于每一个时机, 也可以进行不同的操作.
4. 再谈,前序,中序与后序遍历
前面介绍walk与visit,以及visit的三个时机,有什么用呢?
我们来看其实际上的一个应用。那就是使用以上的模板改写前序,中序,以及后序遍历的代码。先定义一下TreeNode的结构
class TreeNode { int val; TreeNode left; TreeNode right; TreeNode(int x) {val = x;}}复制代码 我们先来看,如何写前序的代码。
这里,我们需要搞明白,在前序遍历中,visit具体是什么操作,我们不妨就是打印出结点的值。
那么,这个visit操作放到什么时候来做呢?其实就是时机选择的问题,那么前序遍历,就是一到达结点,还没访问左右子结点之前进行操作,所以,我们可以写出如下代码
//前序void walk(TreeNode node) { //走到空结点, 什么也不做 if (node == null) return; print(node.val); //还没进入左右结点 walk(node.left); walk(node.right); return;}复制代码 同理,中序就是从左结点访问回来之后,进行打印,代码如下
//中序void walk(TreeNode node) { //走到空结点, 什么也不做 if (node == null) return; walk(node.left); print(node.val); //从左结点回来啦 walk(node.right); return;}复制代码 同理,后序
//后序void walk(TreeNode node) { //走到空结点, 什么也不做 if (node == null) return; walk(node.left); walk(node.right); print(node.val); return;}复制代码 那么,这和我们平时对前中后序的遍历有什么不同呢?如果我们不使用walk, visit的思路来写的话,是这样子的
void preOrder(TreeNode node) { if(node == null) return; print(node.val); preOrder(node.left); preOrder(node.right); return;}void inOrder(TreeNode node) { if(node == null) return; print(node.val); inOrder(node.left); inOrder(node.right); return;}void postOrder(TreeNode node) { if(node == null) return; print(node.val); postOrder(node.left); postOrder(node.right); return;}复制代码 而walk顺序,就是深度优先顺序,前面说了,对于一个给定的树,只有一种walk顺序,而对于visit却有三种时机,代码如下
void walk(TreeNode node) { if(node == null) return; //operateA() walk(node.left); //operateB() walk(node.right); //operateC() return;}void operateA() {}void operateB() {}void opearteC() {}复制代码 那么就可以说出两者的不同了
使用walk顺序来写三种遍历,其实三种遍历都是同一种顺序,只是visit的时机不同罢了。
而使用三种遍历思想来写三种遍历的算法,你看到的是三种不同的顺序
而以上两点看待问题的角度其实有很大的区别,使用walk顺序不同visit的时机来写,往往能写出更清晰易懂的代码,对于简单的打印可能不明显,下面举一个更复杂的例子。
5. 打印2叉树的所有路径
题目描述见
分析题目, 我们利用一个变量path来记录从root到当前结点的路径.
这里的关键是选择操作的时机,以及做哪些操作.也就是visit的时机,以及visit具体要做什么。
首先, 当我们到达一个结点时, 如果该结点是非叶子结点, 则需要将node.val + "->" 添加到路径中.
如果是叶子结点, 则需要将node.val添加到路径中并且将该路径放到最终的路径集合paths中.
以上可以是时机1做的操作, 代码如下:
static public void append(TreeNode node) { //叶子结点 if (node.left == null && node.right == null) { path.append(node.val); paths.add(path.toString()); return; } //非叶子结点 path.append(node.val + "->"); return;}复制代码 那么还需要做其它的吗?
以上所做的是往路径中添加的工作, 如果我们只加不减, 路径就会包含在其它结点, 这是错误的, 所以但我们离开某一个结点时, 即时机3时, 做以下操作.
static public void strip(TreeNode node) { int valSize = Integer.toString(node.val).length(); if (node.left == null && node.right == null) { path.delete(path.length() - valSize, path.length()); return; } path.delete(path.length() - (2 + valSize), path.length()); return;}复制代码 walk代码,再加上时机一和时机三的操作,就是如下所示代码
static public void walk(TreeNode node) { if (node == null) { return; } append(node); walk(node.left); walk(node.right); strip(node); return;}复制代码 可见,使用walk思想来解决题目主要是考虑清楚两点
- 选择操作的时机
- 具体是什么操作
而如果是, 利用"遍历"的思想, 可能写出如下的代码
public void innerBinaryTreePaths(TreeNode root) { int valSize = Integer.toString(root.val).length(); path.append(root.val); if(root.left == null && root.right == null) { paths.add(path.toString()); path.delete(path.length() - valSize, path.length()); return; } path.append("->"); if(root.left != null) { innerBinaryTreePaths(root.left); } if(root.right != null) { innerBinaryTreePaths(root.right); } path.delete(path.length() - (2 + valSize), path.length()); return; }复制代码 而这种解法,显然不如第一种清晰。
比较两种思想的解法。
- walk与visit思想 :则将访问顺序与操作解耦合, 写代码时, 我们只要关心, 操作的时机以及执行什么操作即可, 写出的代码更加清晰
- 普通遍历思想:则访问顺序与操作耦合在一起,代码混乱不清晰
二 进一步
以上只是介绍了二叉树,其实这种walk与visit具有更普遍的适用性,比如一个多叉树的模板可以是这样
void walk(TreeNode node) { // 进入第一个子节点之前 for(int i = 0; i < node.childRen.length; i++){ // 进入每一个子节点之前 walk(node.childRen[i]); // 从每一个子节点返回之后 } // 从所有子节点返回了}复制代码 实际上, 无论是二叉树, 多叉树, 还是图也好, 其Walk顺序都可以归结为深度优先顺序.
对于二叉树, 访问时机有三个, n叉树, 访问时机有n+1个, 图也是类似.
所以涉及到这几种数据结构的操作, 都可以利用以上所讨论的思想解决.
三 更进一步: 访问者模式
以上只是说明了,其在树,图结构上的应用,但是这种思想可以应用在更加一般化的结构中,我们可以给定任意的结构,然后规定一种顺序,再规定操作的时机和具体操作。这就是访问者模式。
其实这个问题的更一般化问题就是访问者模式, 其思想是将算法与结构分离.
详细介绍见
四 总结
walk与visit思想的本质是:
将在一个数据结构上的操作与该数据结构分离
转载地址:http://xgazb.baihongyu.com/